
The Context Tax
How your AI system remembers, and why most don't

At Makers & Breakers, I write about what it actually takes to build products; the engineering, the leadership, the systems thinking. These pieces come from real projects and real mistakes. Some challenge assumptions. Most just try to be honest about what I’ve seen work and what hasn’t.
This is Part 2 of a series. If you missed the first part, start with The Narrow Landing Surface.
Part 1 described the problem. Your existing project has a narrow landing surface. The model aims for the consensus centre. Without structure, every session drifts a little further from the architecture you designed. A harness — constraints that persist between sessions — is the first layer of the fix.
But constraints alone aren’t enough. Teams that stay in control have built a system. Most are still running a series of isolated interactions and calling it a workflow.

You already have a system
Even if you haven’t designed one, you’re running one.
You’ve seen what it looks like. A developer pair-programming with an agent, watching every line like a hawk, trying to catch mistakes before they land. Judging the output hard. Deliberately trying to make the agent fail so they can spot the failure before it ships. Every session improvised. No guardrails. No accumulated knowledge from the last session. Just a human running full-intensity quality control with their own attention as the only safety net.
That works until they blink. And they always blink — because attention doesn’t scale and the agent doesn’t get tired.
That developer is already running a system. Their codebase is the memory, their prompts are the control inputs, their eyeballs are the evaluation layer, and their conventions — stored nowhere but their head — are the constraints. The problem is that all of it is implicit, manual, and non-transferable.
Teams that stay in control make four layers explicit:
Constraints define what “correct” means. Which libraries, which patterns, which deliberate divergences from the consensus.
Orchestration determines how work flows. Not one prompt producing one output, but a pipeline: read existing pattern, generate following that pattern, validate conventions, integrate.
Evaluation verifies correctness, not plausibility. The most consistently missing layer. Without it, “it compiled” becomes “it works.”
Feedback makes corrections permanent. Not a one-time fix to a single file, but an update to the constraints, the orchestration, or the evaluation rules.

These four layers form a loop. AI generates output, evaluation checks it, corrections feed back into the constraints, and the next session starts from a better position. Drift lives in the loop. Fix the loop, drift stops.
Most teams have all four layers implicitly — and that works while the team is small and the people prompting are the ones who designed the architecture. It stops working at scale. The transition from accidental to intentional is gradual: making each layer explicit, one at a time. And the first one most teams get wrong is memory.
The context tax
The model doesn’t remember. It has no state between sessions. Every conversation starts from zero. Whatever it “knows” about your codebase comes from what you feed it right now, in this session, through this context window. If you fed it nothing, it would generate code aimed at the consensus centre of its training data — the drift problem all over again.
You could solve this with a CLAUDE.md or a system prompt that says: here are the rules, here are the conventions, here’s what you need to know. It works. For a while.
Then the file grows. It grows because the project grows. Every new convention, every new integration, every architectural decision that the model keeps getting wrong — you add a line. I’ve seen this happen on our own projects. A couple of months in, you have a 2,000-line document loaded into every session regardless of what the session is about. A developer fixing a CSS bug loads the same context as one designing a new API endpoint. A one-line typo fix pays the same token cost as a full feature build.
That’s the context tax. You’re paying for the model to process a thousand lines of context it doesn’t need for this task.
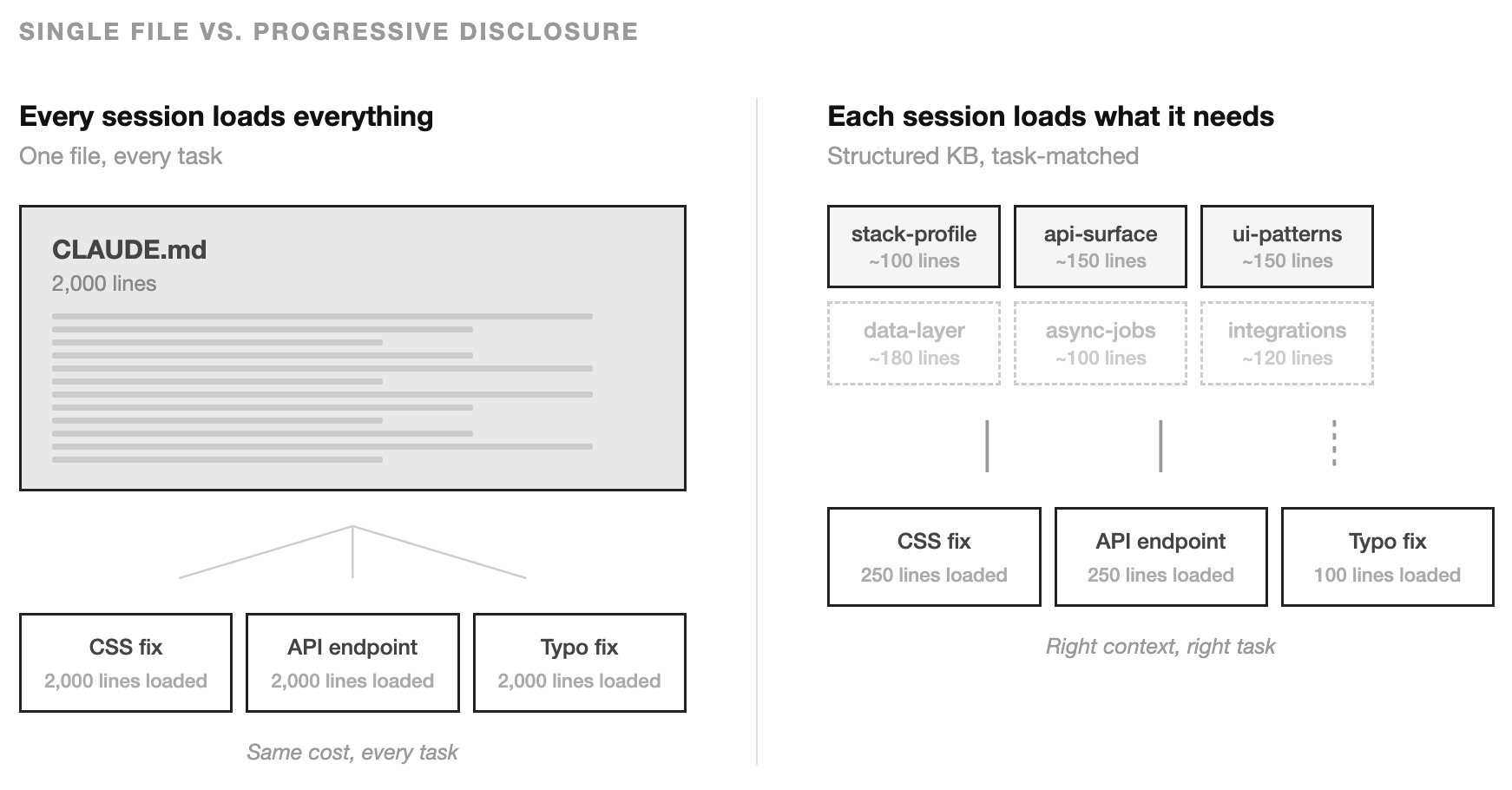
The fix is counterintuitive: give the model less. But the right less — the right context, for the right task, at the right time. In UI design this is called progressive disclosure: don’t show every option on the first screen, reveal complexity as the user needs it. The same principle applies to what you feed an AI. Start with the minimum. Expand only when the task demands it.
Most discussions about AI memory skip straight to the sophisticated end — vector databases, semantic retrieval, knowledge graphs. That skips the part that actually matters: figuring out what to remember and when to surface it.
The maturity ladder
There’s a natural progression. Teams don’t skip levels, even if they think they do.

3Level 0 — No memory
This is vibe coding. The model gets your prompt and whatever files it reads from the codebase. No persistent context. No conventions documented. No constraints encoded.
Every session re-discovers your architecture from scratch. If the most visible pattern in the codebase is the correct one, you’re fine. If the most visible pattern is one the model generated last week — the one that drifted slightly from your actual conventions — you’ve just reinforced the drift.
Level 1 — The single file
A CLAUDE.md, a system prompt, a rules file. Everything the model needs to know, in one place, loaded every session.
This is a genuine improvement. The model stops guessing your GraphQL client. It knows the route conventions. It respects the auth wrapper. For small projects with few conventions, this is sufficient. Some teams stay here permanently and that’s fine.
The failure mode is growth. The file becomes a kitchen drawer. Critical architectural decisions sit next to formatting preferences sit next to outdated notes nobody cleaned up. Everything loads every time. A session that only touches the frontend still ingests 400 lines about the backend job queue. The model processes all of it, which means it’s processing noise alongside signal, and the noise costs you in both token spend and output quality.
There’s a subtler problem: contradictions. A file that grows organically develops internal conflicts. Line 12 says “use server components by default.” Line 847 says “wrap data-fetching in client-side hooks for caching.” Both were true when written. Neither author knew about the other’s line. The model sees both, picks one, and you won’t know which until you read the diff.
Level 3 — Retrieval infrastructure
At some point, files aren’t enough. The knowledge base has 3,000 entity pages. You need to query across relationships, track what was true last quarter versus now, or search by meaning when the developer’s terminology doesn’t match the knowledge base’s.
This is where systems like gbrain and mempalace live. gbrain adds a PostgreSQL retrieval layer on top of a markdown repo — the markdown stays the source of truth, the database makes it searchable at scale. mempalace organises memory hierarchically and loads it in layers, from always-on identity facts down to deep semantic search triggered on demand. Different architectures, same insight: structure improves retrieval more than better embeddings do.
Both are real and production-grade. Both solve problems that flat files can’t. And both are the wrong place to start.
Why you start at Level 2
The instinct is to skip ahead. Same reason teams reach for microservices on day one — if it’s better at scale, why not start there?
Because Level 3 systems are operational commitments. Databases, indexing pipelines, sync mechanisms. They need maintenance, monitoring, and someone who cares when they break at 2am and the agent starts hallucinating on stale embeddings.
But the real reason to wait is simpler: most teams haven’t figured out what knowledge actually matters per task. A vector database will embed and retrieve whatever you put in it. If what you put in is noise, the retrieval will be fast and useless. Semantic search finds what’s similar to the query. It has no idea what’s relevant to the task.
Level 2 forces you to answer that question. When you’re writing a 150-line summary of your data layer, you have to decide: what does a model actually need to know to work correctly here? What can it derive from reading the code directly? What would actively mislead it if included? These are hard editorial decisions — and they’re exactly the decisions that determine whether any memory system works, file-based or not.
Garry Tan built gbrain’s retrieval layer after the markdown knowledge base had been running for weeks/months. The knowledge model was proven before the infrastructure was built. That sequence matters.
Start with files. Learn what the model needs. Learn what it doesn’t. If you hit a real wall — 3,000 entities, cross-referencing, temporal queries — you’ll know exactly what to build, because you’ll have spent months doing it by hand.
Progressive disclosure in practice
So what does Level 2 actually look like? We built a skill — a structured instruction file that an AI agent can execute — called /harness:init. Its job is to analyse a codebase and produce a knowledge base. A curated, structured summary where each file covers one domain and loads only when that domain is relevant.
The skill scans the repository and produces six files:
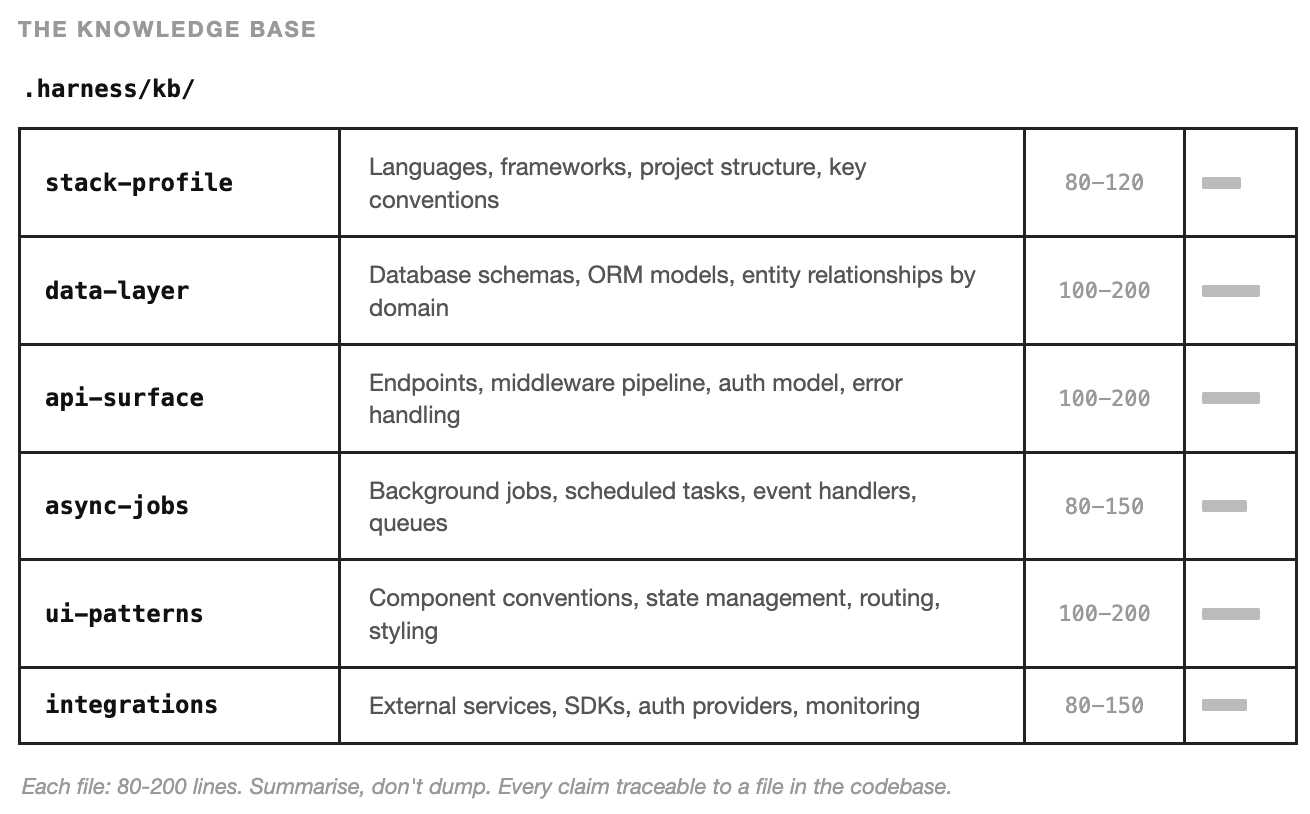
Each file has explicit constraints: 80–200 lines. Summarise, don’t dump. Every claim traceable to a file in the codebase. Tables for entities and endpoints, not prose descriptions. If a category doesn’t apply — no database, no background jobs — say so in two lines rather than inventing content.
The constraint on length is not arbitrary. It’s the mechanism that forces curation. A 200-line summary of your data layer cannot include every column of every table. It has to capture the relationships, the important constraints, the patterns a model would need to understand before modifying that layer. Writing the summary requires understanding which details matter — and that understanding is the thing Level 3 systems need but can’t generate for you.
How progressive disclosure works with these files
An agent working on a new API endpoint reads stack-profile.md (what framework? what conventions?) and api-surface.md (what’s the existing pattern? what middleware? what auth?). It doesn’t read ui-patterns.md because it doesn’t need to know about React component conventions to write a backend route.
An agent working on a frontend component reads stack-profile.md and ui-patterns.md. If the component fetches data, it also reads api-surface.md to understand the endpoint patterns. It never reads async-jobs.md.
An agent debugging a background job failure reads async-jobs.md and data-layer.md. That’s it.
The loading decision can be explicit — a skill that says “read these files before starting” — or implicit, where the agent reads a high-level index and decides which files are relevant. Either way, the pattern is the same: the agent starts with the minimum context required and expands only as the task demands.
What this gets you
Before we built this, a session working on admin data tables would routinely import the wrong GraphQL client, miss the provider hierarchy, or invent a new column-definition pattern that diverged from the five existing tables. After: the agent reads the UI patterns file, sees the established conventions, follows them. Not because we told it “use URQL” — that’s Level 1, the single constraint. Because we gave it a structured understanding of how admin tables work in this codebase: the data-table pattern, the provider wrapping, the column definition conventions, the auth guard, the import paths.
A constraint tells the model what’s correct. The knowledge base shows it what correct looks like in practice. Constraints prevent obvious errors. Context prevents subtle ones.
Regeneration over maintenance
One design decision I debated longer than expected: the knowledge base is regenerable, not maintained. When the codebase changes significantly — new framework, restructured modules, new integration — you re-run the init skill. It scans the current state and produces updated files.
I initially tried maintaining KB files by hand. It lasted about two weeks before the drift was visible. A maintained knowledge base drifts the same way code documentation drifts. Someone updates the code but not the docs. Someone adds a new integration and forgets to update integrations.md. Over time, the knowledge base develops the same contradictions as the single-file approach, just spread across more files.
A regenerable knowledge base treats the codebase as the source of truth and the KB files as a computed view of it. Stale? Regenerate. Wrong? Fix the codebase, then regenerate. The KB is a cache, not a record.
The KB does nothing on its own
A directory of markdown files sitting in .harness/kb/ is inert. No agent reads them unless something tells it to. This is the part most people miss: the knowledge base is step one, not the whole solution. Step two is wiring it into the instructions that govern every session.
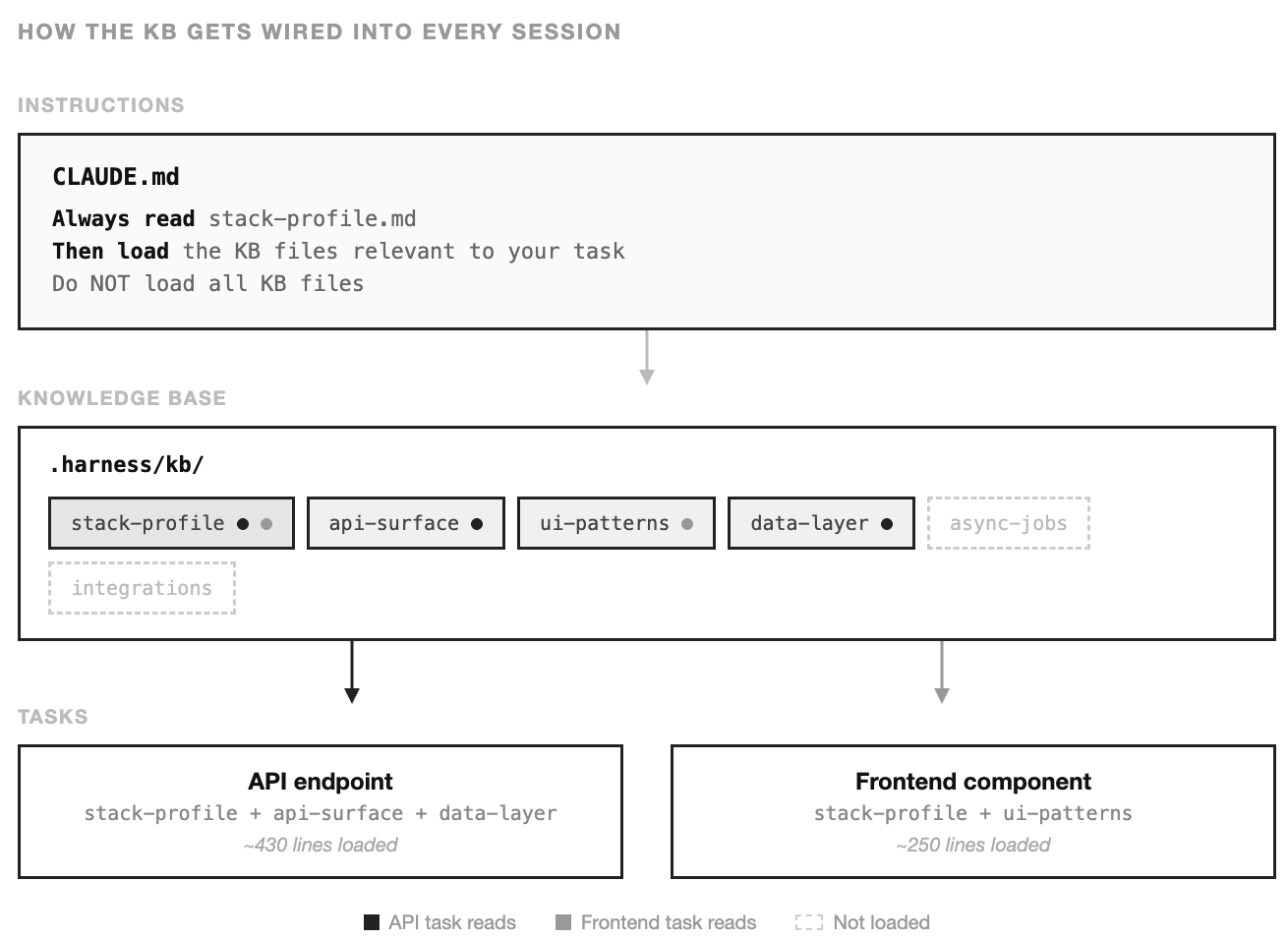
Here’s what that looks like. In your project’s CLAUDE.md — the file that loads automatically at the start of every session — you add a section that turns the KB from passive reference into active context:
Knowledge Base
Before starting any task, read `.harness/kb/stack-profile.md` for project
conventions. Then load the KB files relevant to your task:
- Working on API routes or backend logic → read `api-surface.md` and `data-layer.md`
- Working on frontend components → read `ui-patterns.md`
- Working on background jobs or async processing → read `async-jobs.md`
- Working on external service integration → read `integrations.md`
- Touching database schemas or migrations → read `data-layer.md`
Do NOT load all KB files. Load only what your task requires.
After reading the relevant KB files, verify that your implementation follows
the patterns described in them. If you encounter a pattern in the KB that
conflicts with what you see in the codebase, flag it — the KB may need
regeneration.Ten lines. That’s all it takes to turn the KB from documentation into a protocol. stack-profile.md always loads — it’s the identity layer, the minimum the model needs to orient itself. Everything else loads conditionally. And that final line, “flag conflicts,” is quietly important: it’s the beginning of a feedback loop. When the agent notices the KB disagrees with the codebase, that’s a signal to regenerate.
The same pattern scales into skills and agent definitions. A skill for building API endpoints can include “read api-surface.md and data-layer.md before generating” in its instructions. A code-review agent can include “check the output against the conventions in ui-patterns.md.” Each skill becomes a specific instance of progressive disclosure — loading exactly the context that task requires and nothing else.
This is the foundation. Every skill, every workflow, every agent definition that follows builds on top of this knowledge base. The KB is ground truth. The skills are workflows that consume it. Neither works without the other.
When to graduate
Level 2 has real limits. You’ll know you’ve hit them when:
The knowledge base is stale more often than it’s current. If your codebase changes fast enough that regenerating the KB weekly isn’t enough, and daily regeneration wastes too much time, you need incremental indexing — the kind gbrain provides, where changing one file updates only the relevant entries.
You need to query across entities. “Which services depend on the payments integration?” is a relationship query. A markdown file can answer it if someone wrote the answer down. A knowledge graph answers it structurally, even when nobody anticipated the question. Once you’re asking questions that span multiple KB files and require combining information, flat files become friction.
You need temporal awareness. “What did our auth setup look like before the migration?” The file-based KB only has the current state. If your work requires understanding what changed and when, you need state that flat files can’t represent.
Your team is large enough that file conventions don’t hold. Two people can agree on a KB structure verbally. Ten people will produce inconsistencies that compound. At team scale, the structure needs enforcement — schemas, validation, tooling — that a directory of markdown files doesn’t provide.
Most teams won’t hit these limits for months. Some won’t hit them at all. And by the time you do, you’ll have built the understanding that makes Level 3 successful — you’ll know what knowledge matters, how to partition it, and which tasks need which context. You won’t be deploying retrieval infrastructure and hoping. You’ll be encoding a system you’ve already proven by hand.
What compounds
Context infrastructure is the part of the system nobody sees. There’s no UI for it. It doesn’t ship features. It’s a directory of markdown files and ten lines in a CLAUDE.md that most people would scroll past.
But it changes everything downstream. Every skill that loads the right KB file before generating code. Every review agent that checks output against documented conventions. Every session that starts from an informed position instead of re-discovering the architecture from scratch. The compound effect is invisible on any given day and unmistakable over a month.
We’re still building the layers on top — orchestration that breaks tasks into steps, evaluation that catches what context alone can’t prevent, feedback that turns corrections into systemic improvements. Those are the next article. The KB is where the system starts to feel like a system instead of a series of prompts.
A more capable model with precise context compounds the advantage week over week. A more capable model with noisy context just produces more confident noise. The model is a commodity. The context pipeline is not.
Let’s keep pushing forward!
— Luka
Great piece, Luka. Spot on about the power of Level 2. It’s worth noting that highly capable agents like Claude Code and Codex don't even use RAG. They rely purely on progressive discovery via agent instruction files and codebase tool calls.
A prime example is the OpenClaw repo. It's a showcase in Level 2 done right, with an comprehensive document structure covering decisions, patterns, and components.
"If it compiles, it works" really hit home for me. Been there 😂.
That’s exactly why the evaluation layer in your framework is so critical. The ability to give an agent a feedback loop to test and validate its own work and having those corrections feed back into the constraints permanently is the only way to actually scale this beyond isolated sessions.
Solid series. Looking forward to the next piece