
The Feedback Loop
Autonomous execution, review gates, and how corrections flow back into the system

At Makers & Breakers, I write about what it actually takes to build products — the engineering, the leadership, the systems thinking. These pieces come from real projects and real mistakes. Some challenge assumptions. Most just try to be honest about what I’ve seen work and what hasn’t.
This is Part 4 of a series. If you missed the earlier parts: Part 1: The Narrow Landing Surface · Part 2: The Context Tax · Part 3: The Orchestration Layer.

Wednesday morning. Five PRs in my queue from missions that ran overnight. The reviewer flagged two of them. I read those two — opened the diffs, looked at what the gates caught, sent one back, approved the other after a small fix. The other three had clean signals across the board. I trusted them. They merged.
Twenty minutes from sitting down with coffee to seven commits on main. None of the code was mine. Most of what’s changed about how I work this year is in that paragraph.
Letting the system run feels like letting go of the wheel. Half the time you white-knuckle it — open every PR, read every line, second-guess every gate. The other half you stop watching, then realise a week later you’ve been shipping slop. The art of this piece is the part in between: the gates and the loop that let you stop watching without going blind.
Think of it as a kitchen. The forward arrow is cooking — the model preps ingredients, fires the pans, plates the dish. The backward arrow is tasting before it goes out, and writing in the cookbook for next time. Without both, you ship faster, and most of what you ship is undercooked.
Parts 1–3 built the forward arrow: harness, knowledge base, orchestration — ending in a grounded spec.
Then the grounded spec runs without you.
What the backward arrow gives you is signal — architecture holding, code design clean, layout intact, logic correct, flows working. Five signals, five gates, all of them downstream of where the work happens. Without them, you’re trusting the upstream pipeline to be right every time, with nothing to verify when it isn’t. Speed without verification is just faster guesswork.
If you’ve ever come back to a mission’s merges and found the third one needed reverting, you already know the shape of this problem.
Part 4 is the backward arrow — what happens between spec approved and code merged, and how the output still ends up trustworthy when you’re not watching every step.
Two modes, one spec
A grounded spec doesn’t always become a full autonomous mission. What it becomes depends on the work.
Iterate is you and one cook in the kitchen, watching every step. Mission is a brigade of cooks at parallel stations, you tasting at the pass.
Two modes cover most of what I ship.
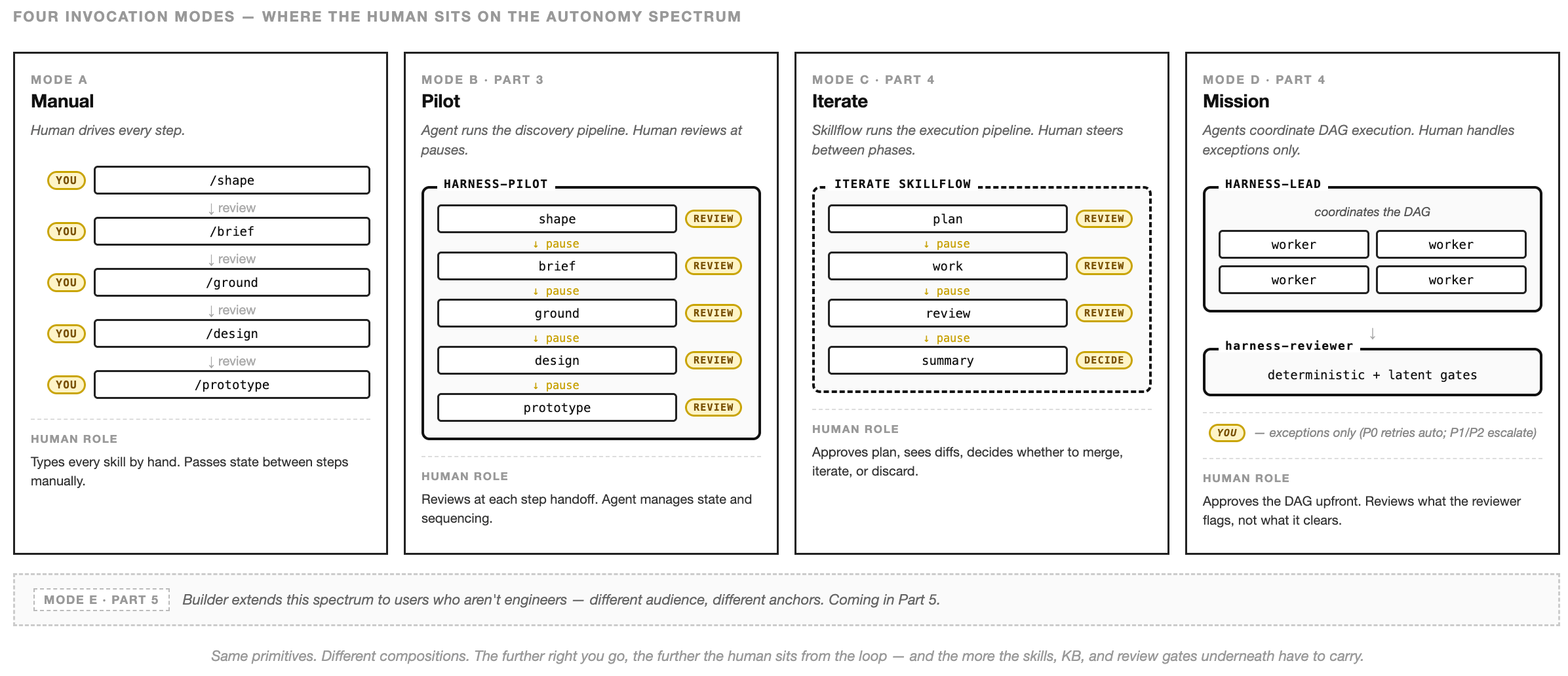
Iterate — a single feature, fix, or contained change, run as a semi-supervised session. The flow pauses between phases: plan → work → review → summary. I see the plan before work starts, the review before anything merges. I’m in the session.
Mission — a whole spec decomposed into a directed acyclic graph of work units. harness-lead reads the spec, builds the DAG, and dispatches harness-worker agents in isolated worktrees. Workers run in parallel where the graph allows, capped at 3–5 concurrent — a token-budget ceiling, not a correctness one. harness-reviewer gates every merge. I’m not in the session.
Both modes read the same knowledge base. Both commit against the same branch rules. Both feed the same feedback loop. What changes is where I sit and how much of the work runs in parallel.
Both share harness-pilot‘s shape from Part 3 — coordinators wrapping skills, thin body.
---
name: harness-lead
description: Coordinates mission execution by reading the task DAG,
delegating to worker agents, and managing the mission lifecycle.
model: opus
skills:
- harness:init
- harness:ground
---
You are the harness-lead. You coordinate a mission's task DAG by
delegating work to specialised agents. You do not write code — that's
what workers are for. Your job is readiness assessment, task
scheduling, and failure handling.The worker on the other end of the dispatch carries the worktree contract in its own frontmatter.
---
name: harness-worker
description: Executes a single mission task in an isolated worktree.
model: sonnet
isolation: worktree # <- the whole worktree contract
tools:
- Read
- Edit
- Write
- Bash
---isolation: worktree is the line that matters. The Harness daemon reads it, creates a fresh worktree, checks out a task-specific branch, and hands the worker a clean filesystem copy. You never shell out to git worktree yourself. When the worker finishes, it commits inside its worktree and calls harness_submit_for_review — it does not merge. On approval the daemon merges; on rejection or failure the worktree is discarded and the task is re-queued.
That’s the take-home — the worktree juggling and the merge orchestration don’t live in your agent files. They live in the daemon, and you opt in with one frontmatter field.
The plumbing, made boring
Eight daemon RPCs carry the whole mission protocol. A worker or lead never does more than this.
harness_get_mission fetch mission metadata
harness_get_mission_tasks full DAG with statuses + dependencies
harness_claim_task atomic task claim (fails if already taken)
harness_get_task_context task description + parent + upstream outputs
harness_report_progress streaming status to the operator view
harness_submit_for_review worker signals done; transitions to review
harness_approve_task reviewer approves; daemon merges the branch
harness_reject_task reviewer rejects; daemon discards worktree, re-queuesThey drive one small state machine per task.
ready -> claimed -> in_progress -> submitted -> in_review
-> approved (merged) | rejected (discarded, re-queued)And harness-lead is not a daemon component. It's an agent file like any other — same open skill/agent standard — running in its own Claude session, calling the same RPCs. The daemon is a thin coordination service. Everything load-bearing lives in agent frontmatter, skills, and the KB. Which means any piece of this is replaceable without touching the rest. Swap the reviewer. Add a custom worker type. Write a new lead with a different scheduling policy. Nothing downstream notices.
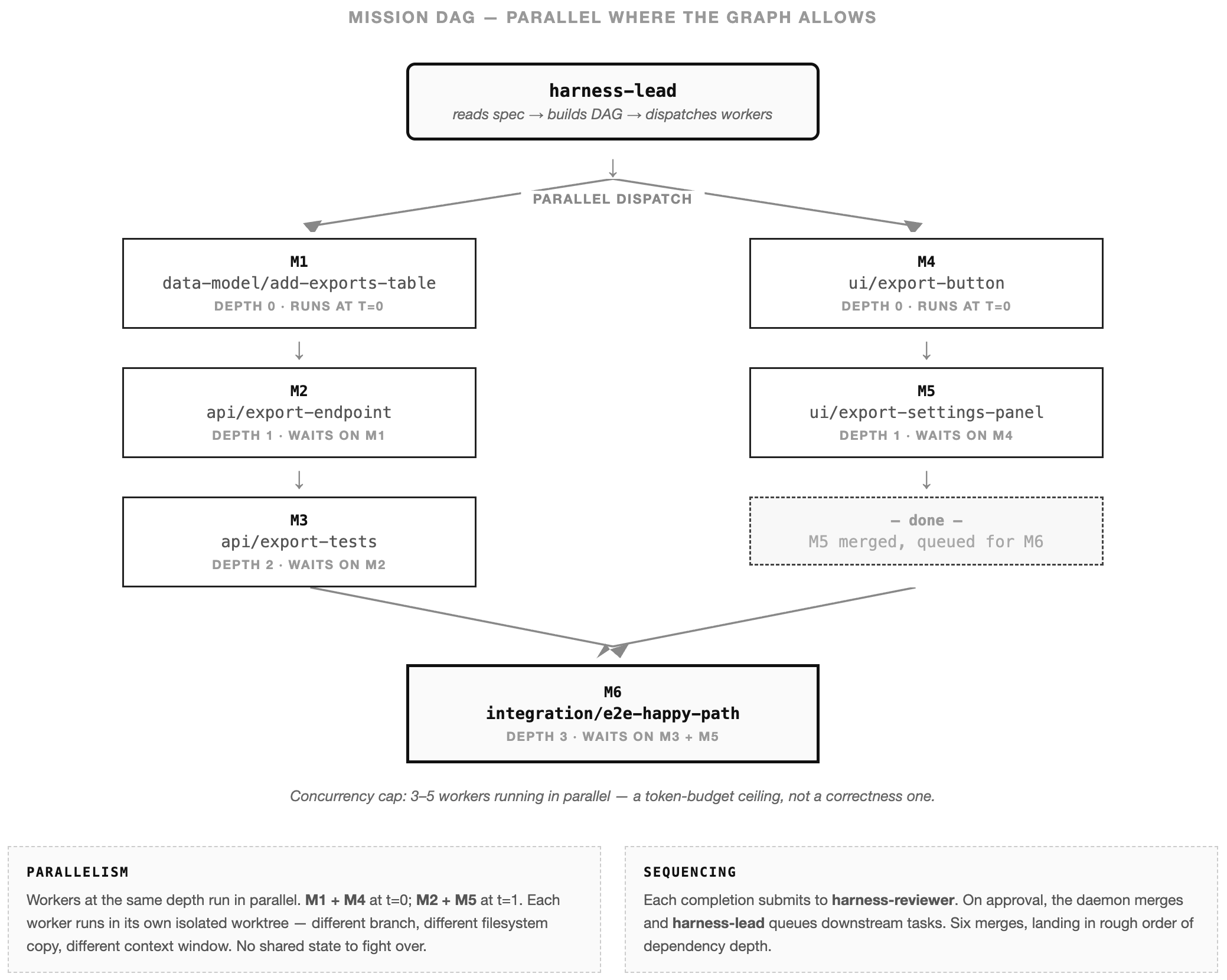
In the DAG above, workers claim M1 and M4 in parallel at t=0. As each finishes, harness-reviewer runs against its branch; on approval the daemon merges, and harness-lead queues the downstream tasks. Six merge commits, landing in rough order of dependency depth.
Workers never collide because each one runs in its own branch on its own filesystem copy with its own context window — the kind of isolation you’d build by hand if you were trying to set up six engineers to ship in parallel without stepping on each other, except the daemon does the setup. Failure is cheap. A rejected worktree is thrown away at zero cost to the rest of the mission. Mistakes don’t compound across workers; they die in their own branch.
The mode choice is a bet on autonomy. Iterate for work I want to steer. Mission for work I’d rather review at the gate than drive step-by-step.
The review gate decomposes
A review gate is two gates stacked behind one door. The commonest mistake in autonomous execution is treating them as one.
Three tasters at the pass. One looking at saltiness. One at doneness. One at presentation. None of them tasting the whole dish.
The distinction is latent vs deterministic — where in the system each kind of decision lives. Every check harness-reviewer runs falls into one of two categories, and they behave differently enough that conflating them costs you.
The deterministic side is cheap and binary. Tests pass or they don’t. Build compiles or it doesn’t. TypeScript type-checks or it doesn’t. Migration runs clean against a production snapshot or it errors. When it fails, the failure is mechanical — broken test, missing type, schema conflict — and you know exactly what’s wrong. No debate, no reading, no judgment.
The latent side is where judgment lives. Does the code follow codebase conventions? Is the abstraction proportional to the feature? Is this the boring solution, or has the worker invented something clever that will haunt someone in six months? These checks need reading, context, taste. They’re slow. The outcome is continuous, not binary. Two senior engineers might rate the same diff differently — and that’s the signal, not the bug.
Splitting the gate makes the failure mode legible. Deterministic checks run first and cheap. If a worker’s output can’t build, latent review never starts — no point reading code that doesn’t compile. Once deterministic checks pass, latent review runs against output that’s at least mechanically correct. What it flags is genuinely about judgment.
My reviewer pushes this further. The reviewer itself is a coordinator — fanning out to parallel sub-reviewers, each with a narrow job:
---
name: harness-reviewer
description: Coordinates review by fanning out to three read-only
sub-reviewers (security, correctness, build) in parallel, then
merging their findings into a single report.
model: opus
tools:
- Read
- Grep
- Glob
- Bash
- Task # <- this is what enables the fan-out
---
You are the review coordinator. You do not review code yourself —
you delegate to three specialised sub-reviewers and merge their
reports.
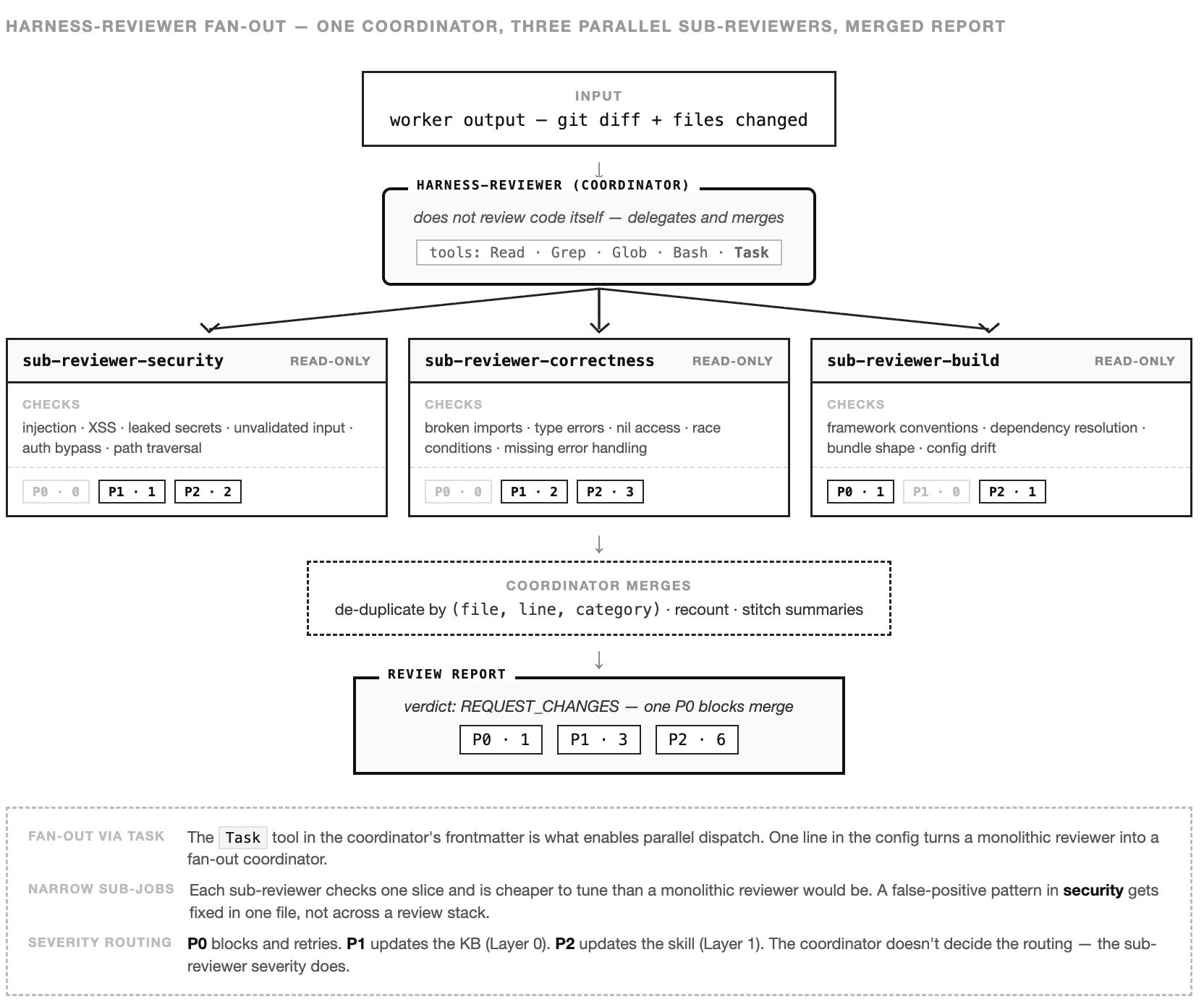
The Task tool in the frontmatter is what turns a monolithic reviewer into a fan-out coordinator — one line in the config.
Three sub-reviewers. Each one hostile to one class of mistake.
Security (harness-reviewer-security) assumes every string is an attacker. It bounces code that interpolates user input into SQL, shells, or template strings that become markup; calls innerHTML with anything that came from a form; passes raw HTML through React’s unsafe-HTML prop; leaks secrets into commits; skips auth at the wrong boundary. It does not negotiate. It blocks.
Correctness (harness-reviewer-correctness) reads the diff plus one hop. Broken imports, undeclared dependencies, type errors, race conditions, error handlers that swallow — all caught before a human ever sees the branch. The sub-reviewer that notices when something compiled but shouldn’t have.
Build (harness-reviewer-build) is the pedant. Invalid Tailwind utility classes. 'use client' in the wrong place — or missing where it must be. package.json versions that won’t resolve together. Mixed CJS/ESM in one file. tsconfig options at war with the Next major. next.config.js that fights the framework. If the build is one character from breaking, Build finds the character.
Each one reads only git diff main --name-only plus immediate imports. The scope cap is load-bearing. A reviewer that reads the whole codebase is a reviewer that returns in an hour with a vague report. We don’t want vague. We want diff, imports, verdict.
Three hostile readers. Narrow briefs. Parallel dispatch. Any one of them can block a merge.
One task’s merged report:
harness-reviewer report task M2 (api/export-endpoint)
verdict REQUEST_CHANGES
findings
P0 build src/api/exports.ts:42
missing return type on exported handler — breaks the public types build
→ retry worker with error attached
P1 security src/api/exports.ts:58
new endpoint doesn't wrap through withOrgAuth() — other handlers do
→ KB entry proposed: api-surface.md (org scoping)
P2 correctness src/api/exports.ts:91
ad-hoc date-range parser; lib/time/parseRange exists
→ skill entry proposed: api-endpoint-skill (use shared time lib)
counts P0·1 P1·1 P2·1
The merged report shows the Part 3 "small rules do the work" pattern applied to review. Narrow sub-jobs. Assembly at the top. Each sub-reviewer is cheaper to improve than a monolithic reviewer would be. Each one's output is diagnosable on its own. When the security sub-reviewer starts flagging false positives, I tune that file, not the whole review stack.
The third gate: visual
If you’ve ever shipped something that compiled, deployed, opened — and then didn’t actually work when a user clicked it, that’s the gap this section closes.
The static gate proves the code compiles, the conventions held, the build passes. None of those is the same as the app works. Reading the recipe is not the same as tasting the dish.
Visual checks fill the gap on three axes.
Runtime. The deploy succeeded, but does the form submit, does the route load, does the click actually land? Build-OK is a precondition, not a verdict.
Structure. Paddings, sizes, alignment — the difference between a UI that renders and a UI that’s usable. The compiler doesn’t see this. The user sees only this.
Paths. Happy, error, edge. Three signals that give a merge real quality, not just type-checked code.
There’s a second-order reason. Asking the model to find the bug by reading the whole codebase is expensive twice over — in tokens, and in trust. The navigation logic drifts. The visual gate works against the deployed surface, scope-narrowed to the changed files plus their assertions. Same principle the static sub-reviewers run on (git diff main --name-only plus immediate imports), applied at runtime.
app-visual-verify closes the gap. A mission stage — sequential, gating — that runs after APP_DEPLOY succeeds.
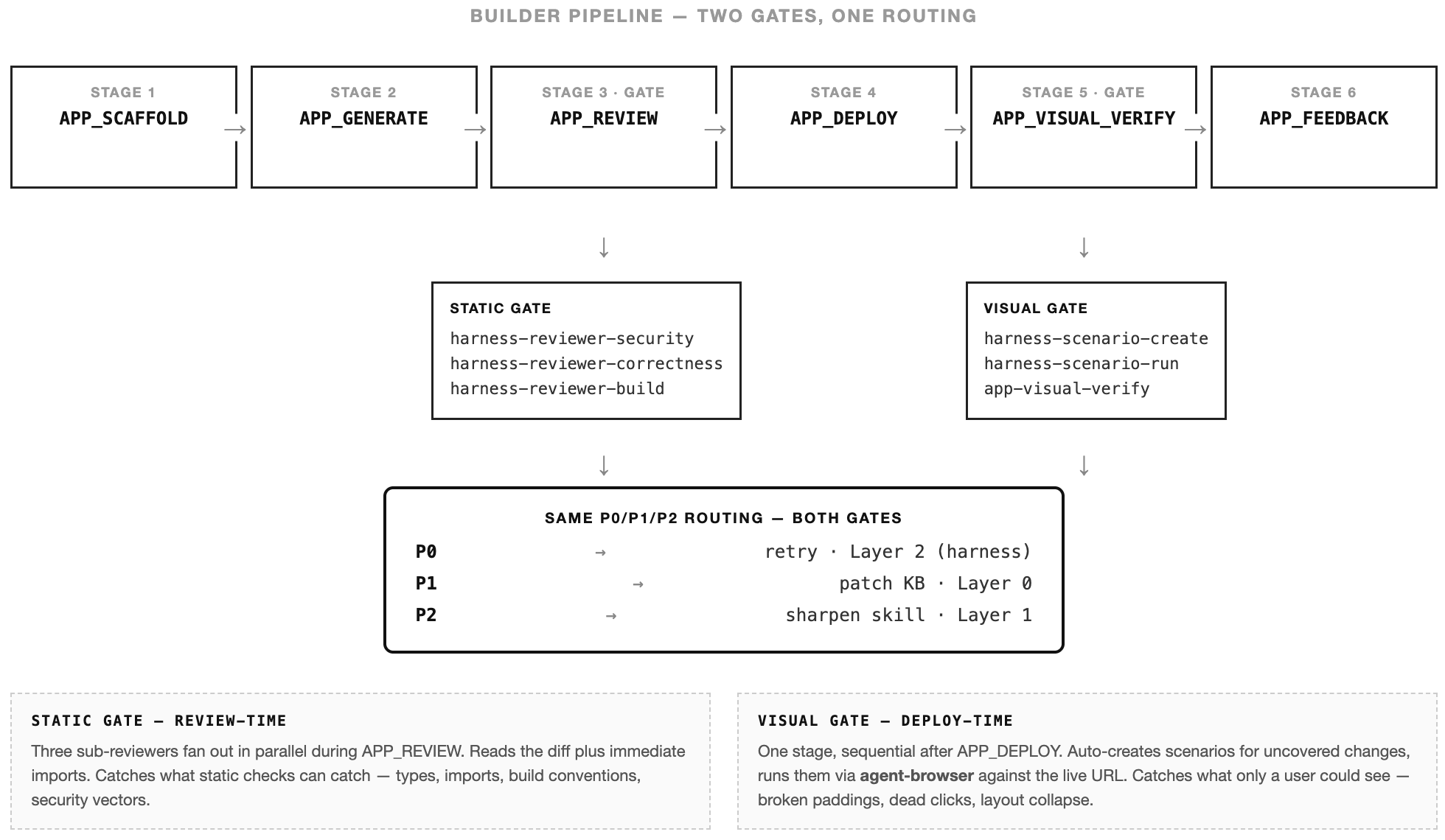
Same review-report shape as the static gate — category: "visual", same findings, same counts: {P0, P1, P2}. Downstream tooling consumes both uniformly.
Three skills do the work.
harness-scenario-create generates .scenario.md files for the changed surfaces. Four buckets: happy path (HP-*), error path (ERR-*), edge case (EDG-*), visual regression (VIS-*). Capped at six scenarios per task — more than that and the task is too broad, split it.
harness-scenario-run executes scenarios against the deployed URL via the agent-browser CLI (Vercel’s headless tool, ref-based selection from accessibility snapshots, not Playwright). Each scenario produces a verdict and a screenshot.
app-visual-verify is the orchestrator. Coverage check first — does any existing scenario reference the changed files? If not, it auto-fires harness-scenario-create to generate them, then runs. New code never ships untested.
The bootstrap interview detects UI repos and emits these three skills by default. Non-UI repos skip the stage; the prerequisite — agent-browser CLI install — is only asked for when it’s earned.
The static gate covers what the compiler can see. The visual gate covers what the user sees. Between them, there isn’t much room left for a broken app to slip through.
Rejection as learning signal
A rejected dish goes back to the kitchen. The cook reads what was wrong, adjusts, and the next plate is better. That’s how a kitchen gets better.
Rejection in the loop works the same way. Every flagged finding from the static gate or the visual gate carries the same shape — a P0/P1/P2 severity, a target file, sometimes a screenshot. Where the correction lands is what makes the loop compound.
Three kinds of rejection. Three destinations.
P0 — retry. Build broke. Test failed. Migration errored. A happy-path scenario didn’t fire. The worker gets the error back, the branch dies, a fresh worktree spawns, the worker retries. Nothing else moves. P0 teaches nothing — the problem is mechanical, the fix is mechanical. Don’t involve humans in mechanics. The retry loop lives entirely in Layer 2 — the harness itself.
P1 — patch the cookbook. Code builds, tests pass, but a latent reviewer catches something structural. The worker used a pattern that conflicts with how the codebase handles auth. Or the error path didn’t surface the failure correctly. Or the empty state was broken. The worker did what it was asked — the system failed to pass down a convention it already knew. Fix the system, not the worker. The correction lands in Layer 0: api-surface.md, data-layer.md, error-handling.md, whichever cookbook entry owns the domain. Every future session reads the updated entry. The same mistake does not happen twice.
P2 — sharpen the recipe. Code is correct, conventions are followed, tests pass. But the reviewer flags something finer — three layers of abstraction where one would do, a component named in a way that’s technically fine and quietly wrong, a layout that drifts a few pixels from where it should sit. These are judgment calls the skill itself should have made during generation. The correction lands in Layer 1: the skill body gets a new rule, a preference, a counter-example. The skill’s taste tightens. Next run is smarter than this one.
The two patterns that compound first in my own work are data-layer canonicality and API contracts. The model wants to invent a second way to query the database, a fresh wrapper around an endpoint, a parser that almost matches the existing one. Each is a P1 the first time it slips through. Once the entry is in the cookbook, the next session reads it and stops inventing.
The KB doesn’t get bigger uniformly. It gets denser exactly where the worker keeps trying alternatives. If you’ve watched this happen even once — a recurring mistake stop happening because of one twelve-line entry you wrote last week — the rest of this article reads differently.
That distillation runs as compound-skillflow. After an iterate session or a mission completes, it reads the full session transcript and writes the durable items into docs/solutions/. Same skill across both modes. A convention caught during a mission review updates the KB that iterate sessions read tomorrow.
Capture versus apply
Be honest about what that last step does. compound-skillflow captures — reads the transcript, distils, writes a solution doc to docs/solutions/. That’s where it stops. Its own contract is explicit: read-only on the target repo, no edits to source or KB or skill files, one file per run.
Applying the learning — patching .harness/kb/api-surface.md, adding a counter-example to a skill body, regenerating the KB via /harness:init after a real architectural shift — is a separate step. The two-stage split is the whole point, not a gap.
A solution doc is cheap to generate and safe to review. An automatic patch to a skill file is neither. You want a human reading the captured learning before a skill’s behaviour shifts under the next session.
The loop looks like this.
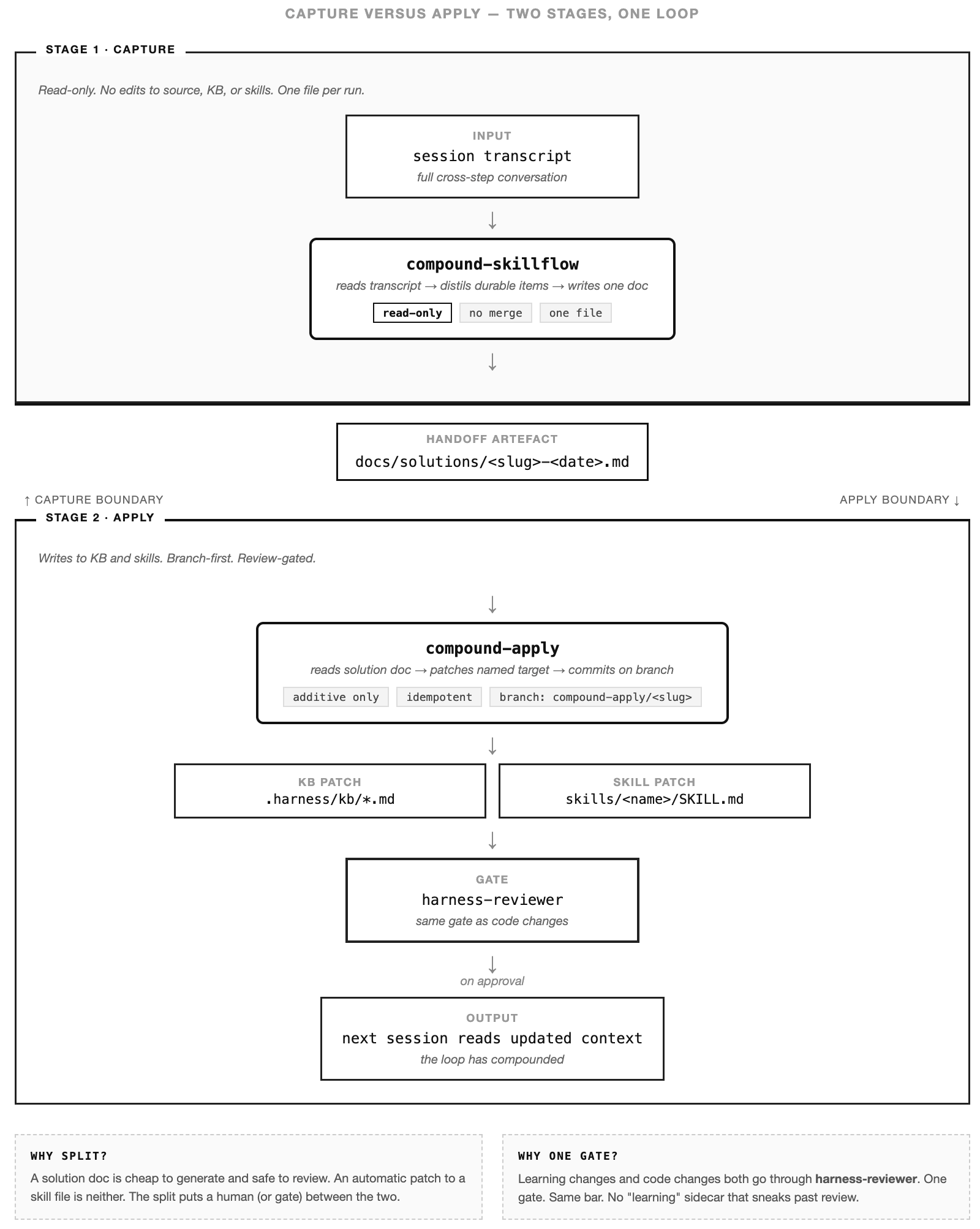
compound-apply is the skill that closes the loop end-to-end. Take a solution doc. Patch the named target. Commit on a branch. Route through harness-reviewer. Learning changes go through the same gate as code changes — because that’s where they belong. Until compound-apply is wired for every target, the last mile is a hand-edit after reading the doc. That’s fine. Earn the complexity.
The review gate’s real job is routing — blocking bad output is the side effect.
Where the human sits
You feel this shift. The first weeks you sit on every PR. Then one Thursday you don’t — and the day still ends fine. That’s the move.
The human moves. And where they move to depends on the mode.
In iterate mode, I sit close. The flow pauses at plan, at work, at review, at summary. I see the plan before anything runs. I see the review before anything merges. I’m not writing code — I’m steering between phases. Right fit for work I want to shape. A feature I haven’t done before. A change in a sensitive part of the codebase. Anything where I don’t yet trust the system.
In mission mode, I sit at the gate. I approve the DAG upfront — is this decomposition right? are any units missing? — and the workers run without me. harness-reviewer handles per-task merges. P0 failures retry themselves. P1 and P2 land on my desk as structured reports. I read what the reviewer flags, not what it cleared. Right fit for work I’ve done the shape of before, in a part of the codebase the KB already knows.
In kitchen terms: iterate is at the stove, every pan in your eyeline. Mission is at the pass, tasting what comes through, not stirring every pot.
Within each mode, two axes refine the position.
Severity class. P0 routes to retry, not to humans. Nobody needs to read a build error — the error is the signal. P1 routes to the KB, with the human either approving the proposed update or writing one. P2 routes to the skill file, which almost always wants a human in the loop for now — judgment about judgment is where humans have the edge, until the skill file catches up.
Confidence. The reviewer can rate its own confidence on latent checks. A high-confidence pass merges. A low-confidence pass escalates. The reviewer saying “I don’t know whether this is the right abstraction” is a more valuable signal than a confident wrong answer. Low-confidence reviews end up on my desk by default.
Start with the human on every channel. Relax per-channel as each one proves itself. Iterate earns autonomy first — the pauses are already there, and it’s easy to shorten the review window once I’ve seen a few clean runs in a domain. Mission earns autonomy last, and unevenly: deterministic gates before latent gates, familiar domains before novel ones.
The human adds the most value where the system hasn’t seen enough examples yet — the contested judgment calls where two reasonable engineers would disagree. Everywhere else, let the gates do the work.
What this doesn’t solve
The loop is powerful, but it’s bounded. Three limits.
Novel problems the system has never seen. The feedback loop teaches the system about things that have already gone wrong once. It can’t teach the system about a category of problem it hasn’t encountered. The first time you touch a new domain — payments, an auth rewrite, a large data migration — the review gate is a tourist. It has no priors on what good looks like in that area, and its latent reviews will be confidently vague. Novel work runs as iterate, not mission. The loop’s value compounds from the second mistake onward.
Taste and product direction. A review gate can tell you whether a feature was built correctly. It can’t tell you whether the feature should exist. Every correction in the loop assumes the direction is right and the execution needs tuning. If the direction is wrong, a tighter feedback loop just gets you to the wrong destination faster. Product judgment stays with humans. No amount of pipeline discipline substitutes for deciding what to build.
Drift toward gameable metrics. A learning system optimises against whatever signal it’s given. If P0 passes means tests green, the system will eventually learn to write tests that go green rather than code that works. If harness-reviewer grades on surface conformance, skills will get better at looking conventional rather than being good. The review gate’s honesty degrades silently, and the output stays plausible while the substance rots. The only defence is periodic audit of the gate itself — reviewing the reviewer, on a schedule, with humans who can tell the difference.
What compounds
Once a domain has been through the loop a few times, the texture changes. You stop watching for drift; the gates absorb it. The mandatory checks (does the happy path work, is the UI rendered correctly, is the error layer doing its job) stop draining mental energy because the gates are doing them.
What’s left is the work that actually wants a human: business rules, user flow, UX judgment. The questions a reviewer can’t answer for you. The reasons you bothered building the thing in the first place.
That’s what compounds. Not the lines of code shipped per week — the fraction of your attention that lands on the work only you can do.
The full stack, made visible.
Each article in this series added a layer, and each layer compounds differently.
Part 1 — the harness — compounds via repeatability. A narrow landing surface. Every session starts from the same shape. Nothing is negotiated fresh.
Part 2 — the knowledge base — compounds via correction. Every mistake caught and written down hardens the context for the next session. The KB gets denser exactly where the work is hardest.
Part 3 — the orchestration layer — compounds via refinement. Each run through the pipeline tightens the skills that run it. Shape asks sharper questions. Ground catches more conflicts. Handoffs close.
Part 4 — the feedback loop — compounds via autonomy. Every reliable gate frees human attention for the next problem. Every correction sharpens the KB and skills that both execution modes read.
Two ideas ran through Part 4. Autonomous execution — workers running without you, the system scaling beyond what one human can supervise. The backward arrow — verification and learning that compound.
Autonomous execution without verification is an AI-slop factory; verification without autonomous execution is a careful, slow system that doesn’t need this much scaffolding to begin with. The leverage is in holding both.
The layers interlock. A harness without a KB is a narrow surface with nothing behind it; a KB without a pipeline is context with no structure; a pipeline without a feedback loop generates work but doesn’t learn from it. Each layer assumes the ones below. Each layer makes the ones above possible.
That’s why the model is the wrong place to look for the edge. Anyone can use Opus. Anyone can use whatever comes after Opus. The compounding lives above the model — in the harness, the KB, the skills, the gates, the loop. All of it designed, refined, and owned by your team.
A month in, the kitchen runs itself. You’re not at the stove. You’re at the pass, tasting two dishes a day, the rest going out clean. The cookbook in the corner has fingerprints on it — entries you remember writing, mistakes you remember catching. You’re back to thinking about the menu, not the mise en place.
The model is a commodity. The system that teaches itself is not.
Try this on your own codebase
All of this is theory until you run it on your own code. Here’s the shortest path.
Copy
bootstrap-harness.mdinto the root of your repo.Open Claude Code in that repo. Say: “Read
bootstrap-harness.mdand start the interview.”Answer its questions — stack, team conventions, where the model keeps getting it wrong, and optionally your voice.
Commit what it writes.
What you get back is a v0 harness for your codebase. A KB seeded from the code you already have. The core skills from this series — shape, brief, design, prototype, ground, iterate, mission, compound-skillflow, compound-apply — wired to your conventions. A review gate with sub-reviewers narrowed to your language and framework. A CLAUDE.md that wires it together.
It will not be complete. That is the point. You earn the rest by running it on real work and patching the gaps. Week one is rough. Week two is where the compounding starts.
The MD file is the whole thing. No CLI. No install. No platform. A markdown file and Claude Code. If the series’ claim is that the system lives in prompts and files, this is where you test it.
—
Luka